


The Dunning-Kruger Effect is much beloved around the internet for the science-and-reason brand dunks it provides. If you’re so sure you’re right, think again: Dunning-Kruger says you may just be one of the massively overconfident dum-dums that psychologists have uncovered. The problem, as has become clear in the last week through multiple blog posts discussing the phenomenon, is that Dunning-Kruger isn’t real. People who know the least about a topic are not the most overconfident.
The reason it’s not true comes down to modeling. In fact, I think the most important point about the Dunning-Kruger debate and debunking is that even doing very simple modeling can give us deep, counter-intuitive insight into how psychological processes work. I won’t rehash the whole debate here. I wrote a blog post about it on Psychology Today, and there have been several other relevant posts. The key insight is that we don’t necessarily know what we would expect the results of an experiment to look like until we actually make specific--mathematically specific--the process that we think generates the data.
With Dunning-Kruger, the observed data does show that people’s self-assessed intelligence is higher than their objectively-assessed intelligence (i.e., the results of a test), and that this difference is larger the lower the person’s score was on objectively-assessed intelligence. The Dunning-Kruger effect also replicates--both using the same measures, and “conceptual replications” (a.k.a. generalizations of the original effect). To someone with my science reform credentials, that should be a great badge of scientific success. We may not be at the mathematical modeling stage yet, but we do know that this is a solid effect. Right?
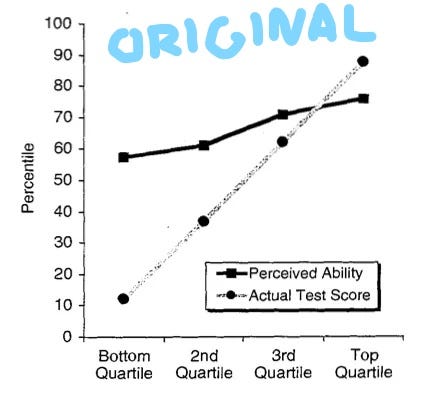
Well, not quite. It turns out that the effect can be reliably generated with a model that actually doesn’t assume that people with less skill are more overconfident. In fact, the Dunning-Kruger effect can be produced through a simple simulation where (i) there is some error in people’s perceptions of their own intelligence (e.g., people don’t know perfectly well how smart they are), (ii) there is some error in test-based measures of intelligence, and (iii) everybody thinks they’re a little smarter than they actually are. Combine these three factors and you can create a figure that looks very similar to the classic Dunning-Kruger effect. This is not the naive interpretation that you get from just looking at the data, even if you trust it to replicate.
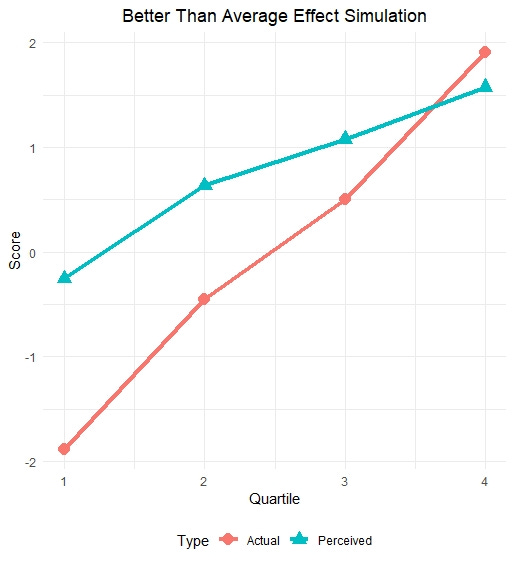
Without doing the modeling, we actually don’t know what processes could be leading to the data we observe. The force of this doesn’t really hit home until you see that, even though we have met all the criteria for Better Science that I think psychology needs--replication, openness, large sample sizes--we still didn’t really understand what we were looking at. In fact, a 2020 paper on Dunning-Kruger worked out the implications of the idea that people who know the least about a topic have the worst insight into their own skill. It turns out what you would observe if this were the case would be heteroskedastic errors in a linear regression, and a nonlinear bend in the relationship between subjective and objective skill. These are the *actual* implications of a Dunning-Kruger model, but we didn’t see it until we simulated those data. The moral is that we need modeling for theory development, and none of the other current reform efforts can take its place.
Now would be the part where I’d expect certain segments of twitter to dunk on open science or replication as unnecessary. The argument might be that modern reform efforts should center modeling, and not push for the rest, because the modeling is what gives us real scientific understanding here. I would also contend that such a hard line is unhelpful. Dunning-Kruger is worth modeling because we have established that it is not just statistical noise, something selectively reported (whether because a PI suppressed other studies or just got lucky with their one study). This is not a safe assumption for most of the psychological literature.
Given what we know about common practices used for decades in psychology research--and given the rough estimates of replication we have for many fields--skepticism should be the default. We should assume that statistical noise and the filter of selective reporting that journal publication implements means that “this is all statistical noise” is a very real explanation that needs to be ruled out before we take effects--and attendant explanations!--seriously. Replication, open materials and data, and even the dreaded preregistration are all tools for ruling out the “All Noise” explanation. I think we need to be realistic about what kind of research is being produced by most psychology researchers right now, and require this extra level of scruple and scrutiny. These worthwhile norms of being more careful and transparent have advanced significantly in the last decade, and I believe this has been a net positive for scientific psychology.
What the Dunning-Kruger effect shows is that science reform can’t stop there. Psychologists need to include theory development in our regular feedback loop of research. This is a necessary next step in scientific reform.
> The problem, as has become clear in the last week through multiple blog posts discussing the phenomenon, is that Dunning-Kruger isn’t real.
Can you link to the blog posts? Now intrigued.
> People who know the least about a topic are not the most overconfident.
But this is exactly what the linked Gignaca and Zajenkowskib (2020) paper shows! It shows that the people who are most confident about a topic *are* the most overconfident, and makes a weak argument that overconfidence does not vary with knowledge (the argument is weak because it treats absence of a statistically significant effect as evidence for the null).
i.e. it matters lot whether or not you take Dunning-Kruger to be a statement about first moments or second moments.
> It turns out that the effect can be reliably generated with a model that actually doesn’t assume that people with less skill are more overconfident.
This is a more compelling argument about first moments, but still doesn't close the logical gap. Now we have two models that produce data like those in the post: one where the Dunning-Kruger effect exists, and one where it does not. The data is compatible with both of these models. Unless we find one of the models substantially better than the other we have no grounds to use one model exclusively for inference!
Personally I do find the measurement error model more appealing than OLS, but there is a lot more argument needed to arrive at a total dismissal of Dunning-Kruger here!